Note
Click here to download the full example code
PyTorch and noisy devices¶
Author: Josh Izaac — Posted: 11 October 2019. Last updated: 9 November 2022.
Let’s revisit the original qubit rotation tutorial, but instead of
using the default NumPy/autograd QNode interface, we’ll use the PyTorch interface.
We’ll also replace the default.qubit device with a noisy rigetti.qvm
device, to see how the optimization responds to noisy qubits. At the end of the
demonstration, we will also show a way of how Rigetti’s QPU can be used via
Amazon Braket.
To follow along with this tutorial on your own computer, you will require the following dependencies:
The Rigetti SDK, which contains the quantum virtual machine (QVM) and quilc quantum compiler. Once installed, the QVM and quilc can be started by running the commands
quilc -Sandqvm -Sin separate terminal windows.PennyLane-Rigetti plugin, in order to access the QVM as a PennyLane device. This can be installed via pip:
pip install pennylane-rigetti
PennyLane-Braket plugin, in order to access the Rigetti QPU as a PennyLane device. This can be installed via pip:
pip install amazon-braket-pennylane-plugin
PyTorch, in order to access the PyTorch QNode interface. Follow the link for instructions on the best way to install PyTorch for your system.
Setting up the device¶
Once the dependencies above are installed, let’s begin importing the required packages and setting up our quantum device.
To start with, we import PennyLane, and, as we are using the PyTorch interface, PyTorch as well:
import pennylane as qml
import torch
from torch.autograd import Variable
Note that we do not need to import the wrapped version of NumPy provided by PennyLane, as we are not using the default QNode NumPy interface. If NumPy is needed, it is fine to import vanilla NumPy for use with PyTorch and TensorFlow.
Next, we will create our device:
dev = qml.device("rigetti.qvm", device="2q", noisy=True)
Here, we create a noisy two-qubit system, simulated via the QVM. If we wish, we could
also build the model on a physical device, such as the Aspen-M-2 QPU which
can be accessed through Amazon Braket (more details on that will follow).
Constructing the QNode¶
Now that we have initialized the device, we can construct our quantum node. Like the
other tutorials, we use the qnode decorator to convert
our quantum function (encoded by the circuit above) into a quantum node
running on the QVM.
@qml.qnode(dev, interface="torch")
def circuit(phi, theta):
qml.RX(theta, wires=0)
qml.RZ(phi, wires=0)
return qml.expval(qml.PauliZ(0))
To make the QNode ‘PyTorch aware’, we need to specify that the QNode interfaces
with PyTorch. This is done by passing the interface='torch' keyword argument.
As a result, this QNode will be set up to accept and return PyTorch tensors, and will also automatically calculate any analytic gradients when PyTorch performs backpropagation.
Optimization¶
We can now create our optimization cost function. To introduce some additional complexity into the system, rather than simply training the variational circuit to ‘flip a qubit’ from state \(\left|0\right\rangle\) to state \(\left|1\right\rangle\), let’s also modify the target state every 100 steps. For example, for the first 100 steps, the target state will be \(\left|1\right\rangle\); this will then change to \(\left|0\right\rangle\) for steps 100 and 200, before changing back to state \(\left|1\right\rangle\) for steps 200 to 300, and so on.
def cost(phi, theta, step):
target = -(-1) ** (step // 100)
return torch.abs(circuit(phi, theta) - target) ** 2
Now that the cost function is defined, we can begin the PyTorch optimization. We create two variables, representing the two free parameters of the variational circuit, and initialize an Adam optimizer:
phi = Variable(torch.tensor(1.0), requires_grad=True)
theta = Variable(torch.tensor(0.05), requires_grad=True)
opt = torch.optim.Adam([phi, theta], lr=0.1)
As we are using the PyTorch interface, we must use PyTorch optimizers, not the built-in optimizers provided by PennyLane. The built-in optimizers only apply to the default NumPy/autograd interface.
Optimizing the system for 400 steps:
for i in range(400):
opt.zero_grad()
loss = cost(phi, theta, i)
loss.backward()
opt.step()
We can now check the final values of the parameters, as well as the final circuit output and cost function:
print(phi)
print(theta)
print(circuit(phi, theta))
print(cost(phi, theta, 400))
Out:
tensor(-0.7055, requires_grad=True)
tensor(6.1330, requires_grad=True)
tensor(0.9551, dtype=torch.float64, grad_fn=<SqueezeBackward0>)
tensor(3.7162, dtype=torch.float64, grad_fn=<PowBackward0>)
As the cost function is step-dependent, this does not provide enough detail to determine if the optimization was successful; instead, let’s plot the output state of the circuit over time on a Bloch sphere:
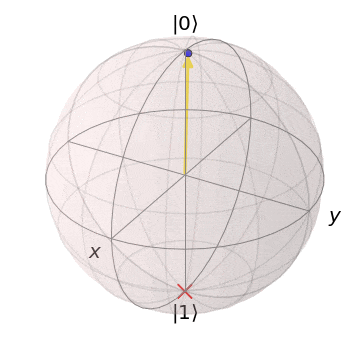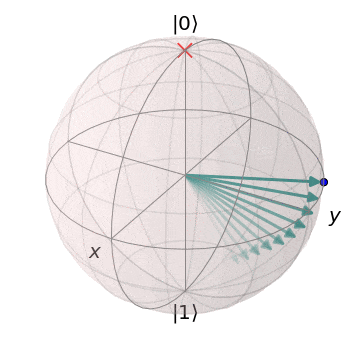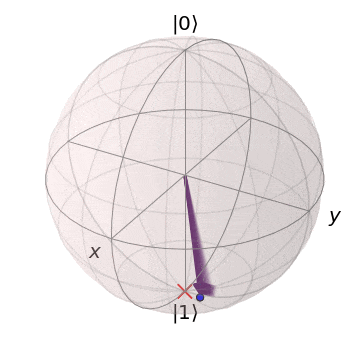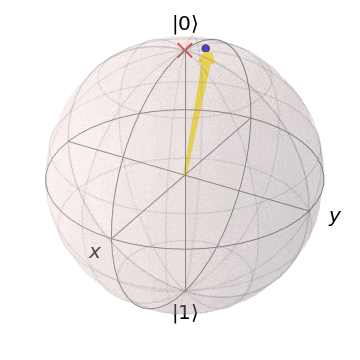
Here, the red x is the target state of the variational circuit, and the arrow is the variational circuit output state. As the target state changes, the circuit learns to produce the new target state!
Hybrid GPU-QPU optimization¶
As PyTorch natively supports GPU-accelerated classical processing, and Amazon Braket provides quantum hardware access in the form of QPUs, we can run the above code as a hybrid GPU-QPU optimization with very little modification.
Note that to run the following script, you will need access to Rigetti’s QPU. To connect to a QPU, we can use Amazon Braket. For a dedicated demonstration on using Amazon Braket, see our tutorial on Computing gradients in parallel with Amazon Braket.
import pennylane as qml
import torch
from torch.autograd import Variable
my_bucket = "amazon-braket-Your-Bucket-Name" # the name of the bucket
my_prefix = "Your-Folder-Name" # the name of the folder in the bucket
s3_folder = (my_bucket, my_prefix)
device_arn = "arn:aws:braket:us-west-1::device/qpu/rigetti/Aspen-M-2"
qpu = qml.device(
"braket.aws.qubit",
device_arn=device_arn,
wires=32,
s3_destination_folder=s3_folder,
)
# Note: swap dev to qpu here to use the QPU
# Warning: check the pricing of Aspen-M-2 on Braket to make
# sure you are aware of the costs associated with running the
# optimization below.
@qml.qnode(dev, interface="torch")
def circuit(phi, theta):
qml.RX(theta, wires=0)
qml.RZ(phi, wires=0)
return qml.expval(qml.PauliZ(0))
def cost(phi, theta, step):
target = -(-1) ** (step // 100)
return torch.abs(circuit(phi, theta) - target) ** 2
phi = Variable(torch.tensor(1.0, device="cuda"), requires_grad=True)
theta = Variable(torch.tensor(0.05, device="cuda"), requires_grad=True)
opt = torch.optim.Adam([phi, theta], lr=0.1)
for i in range(400):
opt.zero_grad()
loss = cost(phi, theta, i)
loss.backward()
opt.step()
When using a classical interface that supports GPUs, the QNode will automatically copy any tensor arguments to the CPU, before applying them on the specified quantum device. Once done, it will return a tensor containing the QNode result, and automatically copy it back to the GPU for any further classical processing.
Note
For more details on the PyTorch interface, see PyTorch interface.
